Lecture 5
Multivariate Gaussians
Marginal and conditional distribution
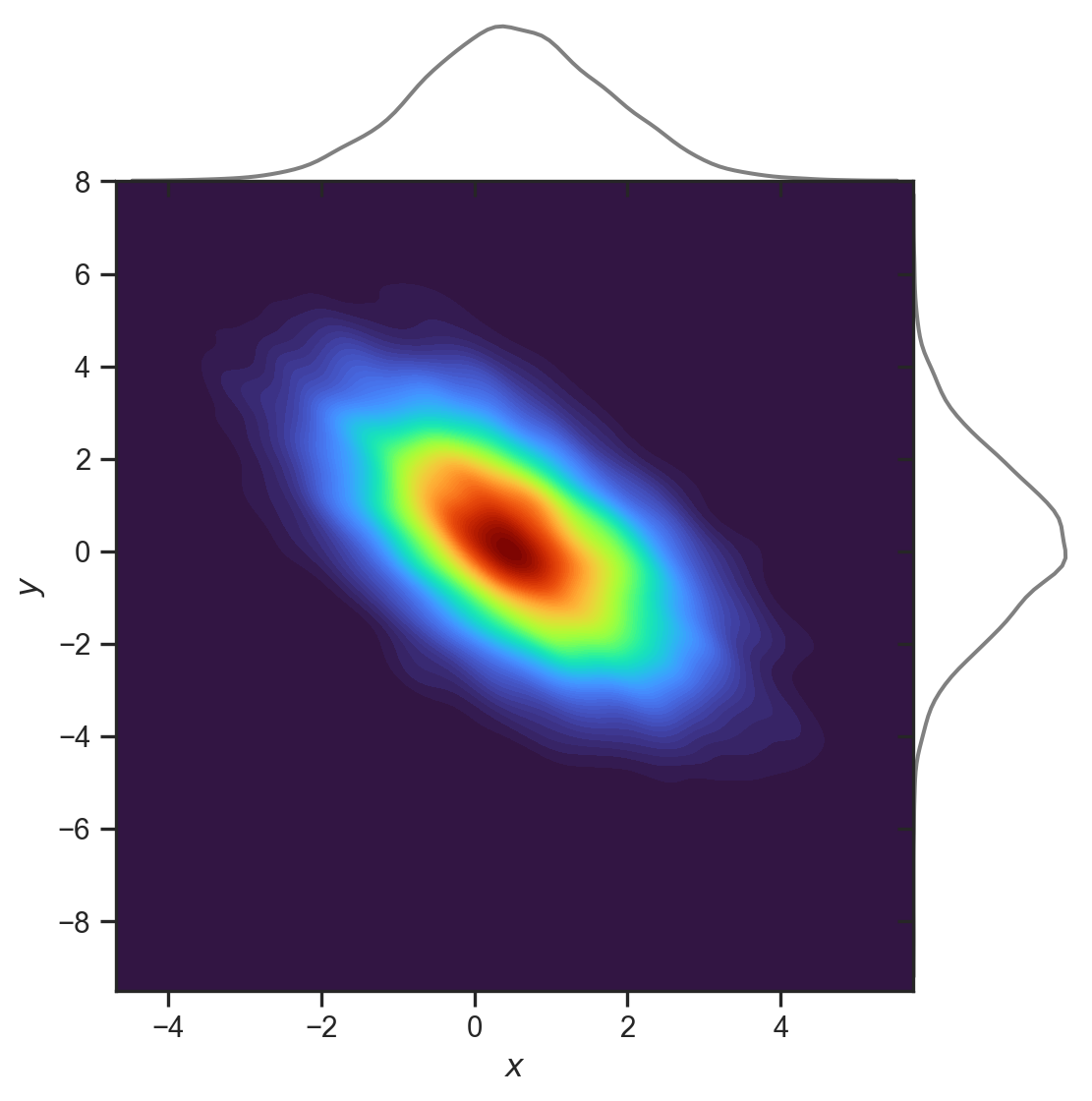
The joint multivariate Gaussian distribution to the left has mean and covariance:
\boldsymbol{\mu}=\left(\begin{array}{c} 0.5\\ 0.2 \end{array}\right),\Sigma=\left(\begin{array}{cc} 1.5 & -1.27\\ -1.27 & 3 \end{array}\right)
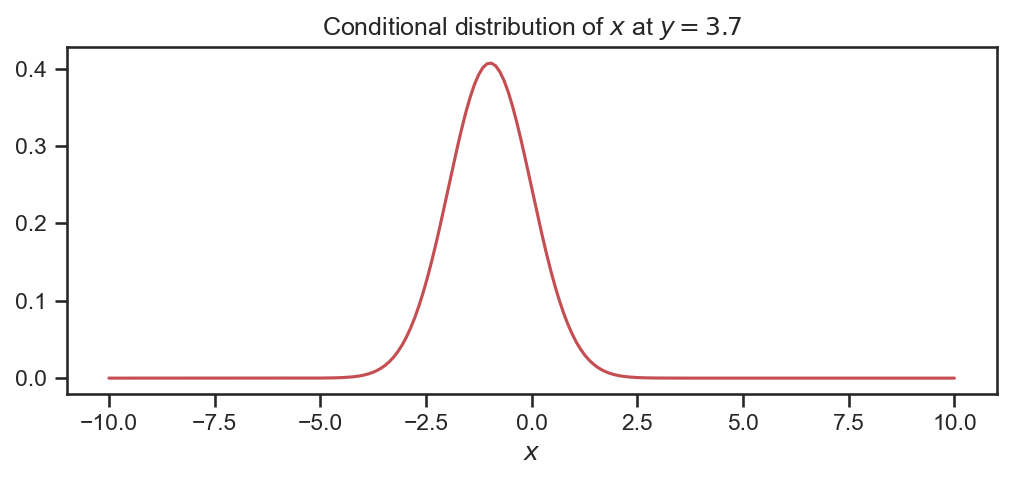
As an example, we wish to work out what f_{X| Y} \left( x, y=3.7 \right) is (see code).
The conditional is Gaussian!
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal, norm
import pandas as pd
import seaborn as sns
sns.set(font_scale=1.0)
sns.set_style("white")
sns.set_style("ticks")
palette = sns.color_palette('deep')
var_1 = 1.5
var_2 = 3.0
rho = -0.6
off_diag = np.sqrt(var_1 * var_2) * rho
mu = np.array([0.5, 0.2])
cov = np.array([[var_1, off_diag], \
[off_diag, var_2]])
rv = multivariate_normal(mu, cov)
# Generate random samples from this multivariate normal (largely for plotting!)
data = rv.rvs(8500)
df = pd.DataFrame({'$x$': data[:,0].flatten(), '$y$': data[:,1].flatten()})
# Now, to plot the conditional distribution of $X_1$ at $X_2=5.0$, we would have
def calculate_conditional(mu, cov, yy):
new_mu = mu[0] + cov[0,1] * (cov[1,1])**(-1) * (yy - mu[1])
new_var = cov[0,0] - cov[0,1] * (cov[1,1])**(-1) * cov[0,1]
return new_mu, new_var
y_new = 3.7
cond_mu, cond_var = calculate_conditional(mu, cov, y_new)
# Now, to plot the conditional distribution of $X_1$ at $X_2=5.0$, we would have
def calculate_conditional(mu, cov, yy):
new_mu = mu[0] + cov[0,1] * (cov[1,1])**(-1) * (yy - mu[1])
new_var = cov[0,0] - cov[0,1] * (cov[1,1])**(-1) * cov[0,1]
return new_mu, new_var
y_new = 3.7
cond_mu, cond_var = calculate_conditional(mu, cov, y_new)
X_samples = np.tile( np.linspace(-10, 10, 200).reshape(200,1) , (1, 2))
X_samples[:,1] = X_samples[:,1]* 0 + y_new
f_X = rv.pdf(X_samples)
rv2 = multivariate_normal(cond_mu, cond_var)
f_X1 = rv2.pdf(X_samples[:,0])
# Plot!
g = sns.JointGrid(data=df, x="$x$", y="$y$", space=0)
g.plot_joint(sns.kdeplot, fill=True, cmap="turbo", thresh=0, levels=100)
g.plot_marginals(sns.kdeplot, color="grey", gridsize=100)
plt.close()
fig = plt.figure(figsize=(8,3))
plt.plot(X_samples[:,0], f_X1, 'r-')
plt.xlabel('$x$')
plt.title('Conditional distribution of $x$ at $y=3.7$')
plt.close()