import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font_scale=1.0)
sns.set_style("white")
sns.set_style("ticks")
palette = sns.color_palette('deep')
df = pd.read_csv('notebooks/data/data100m.csv')
df.columns=['Year', 'Time']
N = df.shape[0]
max_year, min_year = df['Year'].values.max() , df['Year'].values.min()
x = (df['Year'].values.reshape(N,1) - min_year)/(max_year - min_year)
t = df['Time'].values.reshape(N,1)
X_func = lambda u : np.hstack([np.ones((u.shape[0],1)), u])
X = X_func(x)
w_hat = np.linalg.inv(X.T @ X) @ X.T @ t
loss_func = 1./N * (t - X @ w_hat).T @ (t - X @ w_hat)
xgrid = np.linspace(0, 1, 100).reshape(100,1)
Xg = X_func(xgrid)
time_grid = Xg @ w_hat
fig = plt.figure(figsize=(6,4))
plt.plot(df['Year'].values, df['Time'].values, 'o', color='crimson', label='Data')
plt.plot(xgrid*(max_year - min_year) + min_year, time_grid, '-', color='dodgerblue', label='Model')
plt.xlabel('Year')
plt.ylabel('Time (seconds)')
loss_title = r'Loss function, $\mathcal{L}=$'+str(np.around(float(loss_func), 5))+'; \t norm of $\hat{\mathbf{w}}$='+str(np.around(float(np.linalg.norm(w_hat,2)), 3))
plt.title(loss_title)
plt.legend()
plt.savefig('olympics_0.png', dpi=150, bbox_inches='tight')
plt.close()Lecture 6
Linear modelling
Linear least squares
- Consider the data shown in the plot below. It shows the winning times for the men’s 100 meter race at the Summer Olympics for many years.
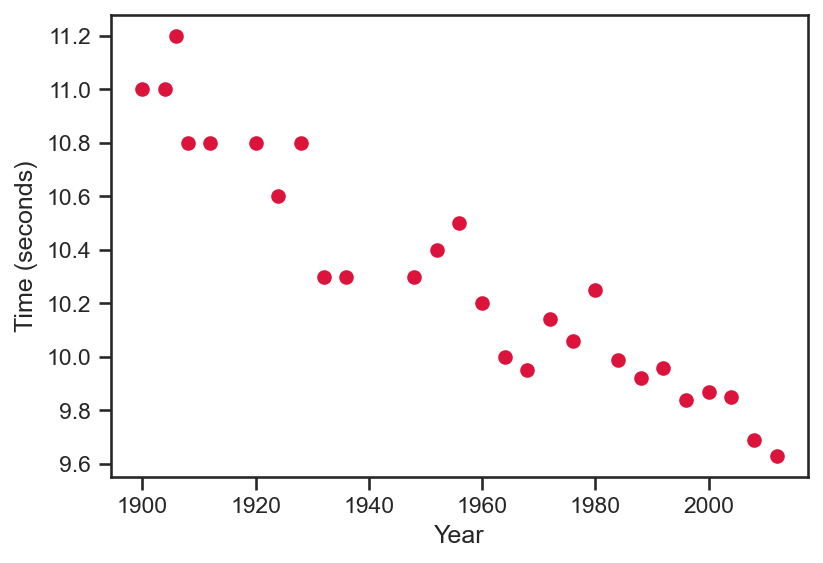
Our goal will be to fit a model to this data. To begin, we will consider a linear model, i.e., t = f \left( x; {\color{blue}{w_0}}, {\color{blue}{w_1}} \right) = {\color{blue}{w_0}} + {\color{blue}{w_1}} x where x is the year and t is the winning time.
{\color{blue}{w_0}} and {\color{blue}{w_1}} are unknown model parameters that we need to ascertain.
Good sense would suggest that the best line passes as closely as possible through all the data points on the left.
Linear least squares
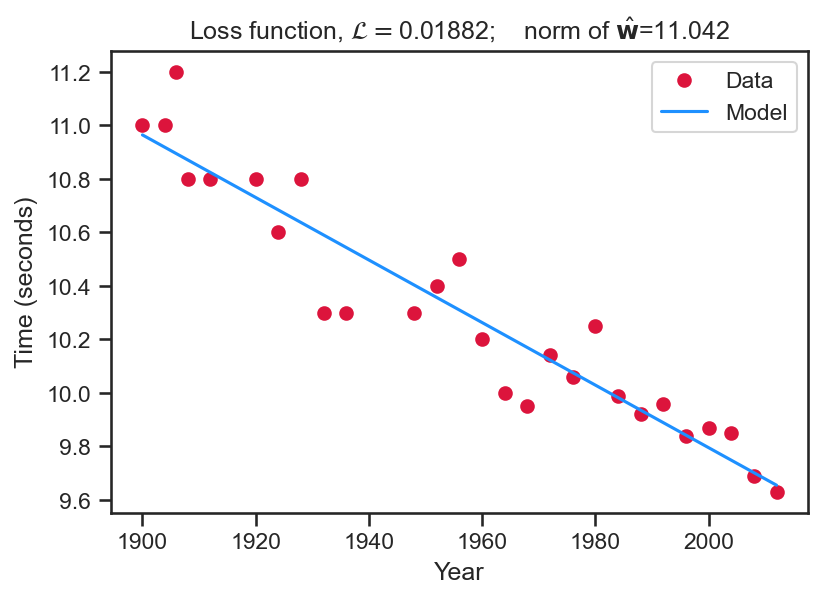
- For this result we set \mathbf{X}=\left[\begin{array}{cc} 1 & x_{1}\\ 1 & x_{2}\\ \vdots & \vdots\\ 1 & x_{N} \end{array}\right] and solve for \hat{\mathbf{{\color{blue}{w}}}} = \left( \mathbf{X}^{T} \mathbf{X} \right)^{-1} \mathbf{X}^{T} \mathbf{t}.
- Once these weights are obtained, we can extrapolate (blue line) over the years.
- Note the graph title shows the loss function value and the L_2 norm, \left\Vert\hat{\mathbf{{\color{blue}{w}}}}\right\Vert_{2}.
Linear least squares
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font_scale=1.0)
sns.set_style("white")
sns.set_style("ticks")
palette = sns.color_palette('deep')
df = pd.read_csv('notebooks/data/data100m.csv')
df.columns=['Year', 'Time']
N = df.shape[0]
max_year, min_year = df['Year'].values.max() , df['Year'].values.min()
x = (df['Year'].values.reshape(N,1) - min_year)/(max_year - min_year)
t = df['Time'].values.reshape(N,1)
X_func = lambda u : np.hstack([np.ones((u.shape[0],1)), u , u**2, u**3])
X = X_func(x)
w_hat = np.linalg.inv(X.T @ X) @ X.T @ t
loss_func = 1./N * (t - X @ w_hat).T @ (t - X @ w_hat)
xgrid = np.linspace(0, 1, 100).reshape(100,1)
Xg = X_func(xgrid)
time_grid = Xg @ w_hat
fig = plt.figure(figsize=(6,4))
plt.plot(df['Year'].values, df['Time'].values, 'o', color='crimson', label='Data')
plt.plot(xgrid*(max_year - min_year) + min_year, time_grid, '-', color='dodgerblue', label='Model')
plt.xlabel('Year')
plt.ylabel('Time (seconds)')
loss_title = r'Loss function, $\mathcal{L}=$'+str(np.around(float(loss_func), 5))+'; \t norm of $\hat{\mathbf{w}}$='+str(np.around(float(np.linalg.norm(w_hat,2)), 3))
plt.title(loss_title)
plt.legend()
plt.savefig('olympics_3.png', dpi=150, bbox_inches='tight')
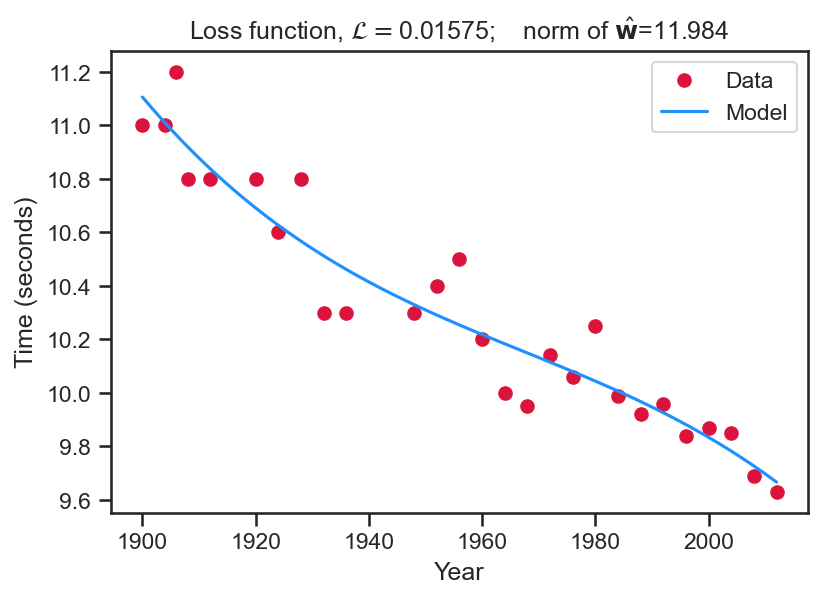
plt.close()- For this result we set \mathbf{X}=\left[\begin{array}{cccc} 1 & x_{1} & x_{1}^2 & x_{1}^3\\ 1 & x_{2} & x_{2}^2 & x_{2}^3\\ \vdots & \vdots & \vdots & \vdots\\ 1 & x_{N} & x_{N}^2 & x_{N}^3 \end{array}\right] and solve for \hat{\mathbf{{\color{blue}{w}}}} = \left( \mathbf{X}^{T} \mathbf{X} \right)^{-1} \mathbf{X}^{T} \mathbf{t}.
- Once these weights are obtained, we can extrapolate (blue line) over the years.
- Note the graph title shows the loss function value and the L_2 norm, \left\Vert\hat{\mathbf{{\color{blue}{w}}}}\right\Vert_{2}.
Linear least squares
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font_scale=1.0)
sns.set_style("white")
sns.set_style("ticks")
palette = sns.color_palette('deep')
df = pd.read_csv('notebooks/data/data100m.csv')
df.columns=['Year', 'Time']
N = df.shape[0]
max_year, min_year = df['Year'].values.max() , df['Year'].values.min()
x = (df['Year'].values.reshape(N,1) - min_year)/(max_year - min_year)
t = df['Time'].values.reshape(N,1)
X_func = lambda u : np.hstack([np.ones((u.shape[0],1)), u , u**2, u**3])
X = X_func(x)
w_hat = np.linalg.inv(X.T @ X) @ X.T @ t
loss_func = 1./N * (t - X @ w_hat).T @ (t - X @ w_hat)
xgrid = np.linspace(0, 1, 100).reshape(100,1)
Xg = X_func(xgrid)
time_grid = Xg @ w_hat
fig = plt.figure(figsize=(6,4))
plt.plot(df['Year'].values, df['Time'].values, 'o', color='crimson', label='Data')
plt.plot(xgrid*(max_year - min_year) + min_year, time_grid, '-', color='dodgerblue', label='Model')
plt.xlabel('Year')
plt.ylabel('Time (seconds)')
loss_title = r'Loss function, $\mathcal{L}=$'+str(np.around(float(loss_func), 5))+'; \t norm of $\hat{\mathbf{w}}$='+str(np.around(float(np.linalg.norm(w_hat,2)), 3))
plt.title(loss_title)
plt.legend()
plt.savefig('olympics_8.png', dpi=150, bbox_inches='tight')
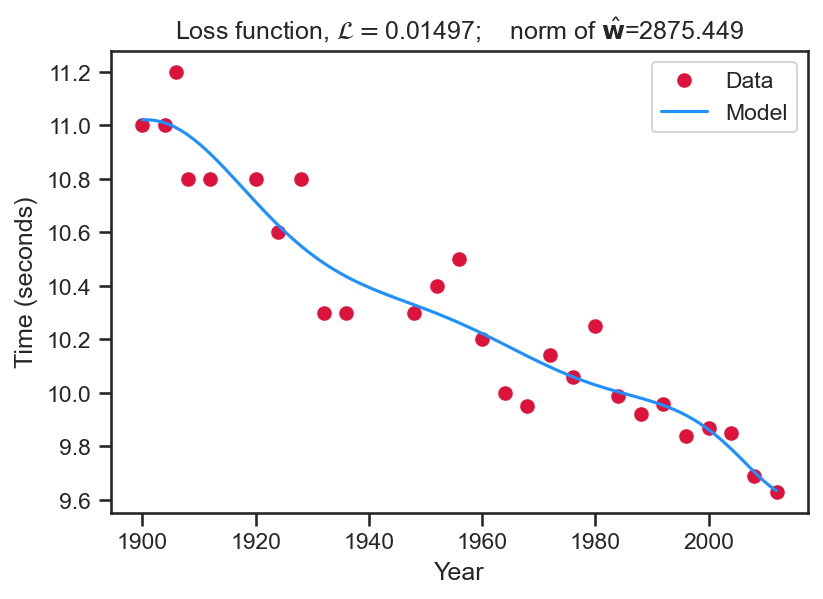
plt.close()- For this result we set \mathbf{X}=\left[\begin{array}{cccccc} 1 & x_{1} & x_{1}^2 & x_{1}^3 & \ldots & x_{1}^{8} \\ 1 & x_{2} & x_{2}^2 & x_{2}^3 & \ldots & x_{2}^{8} \\ \vdots & \vdots & \vdots & \vdots & \ldots & \vdots \\ 1 & x_{N} & x_{N}^2 & x_{N}^3 & \ldots & x_{N}^{8} \\ \end{array}\right] and solve for \hat{\mathbf{{\color{blue}{w}}}} = \left( \mathbf{X}^{T} \mathbf{X} \right)^{-1} \mathbf{X}^{T} \mathbf{t}.
- Once these weights are obtained, we can extrapolate (blue line) over the years.
- Note the graph title shows the loss function value and the L_2 norm, \left\Vert\hat{\mathbf{{\color{blue}{w}}}}\right\Vert_{2}.
Maximum likelihood
Defining the likelihood
If we evaluate the linear model from before, and assume that in Equation 1 \sigma^2 = 0.05, we would find that p \left( t_j | \mathbf{x}_{j} = \left[ 1, 1980 \right]^{T} ,\mathbf{{\color{blue}{w}}} = \left[10.964, -1.31 \right]^{T}, \sigma^2 = 0.05 \right) = \mathcal{N} \left( 10.03, 0.05 \right) This quantity is known as the likelihood of the n-th data point.
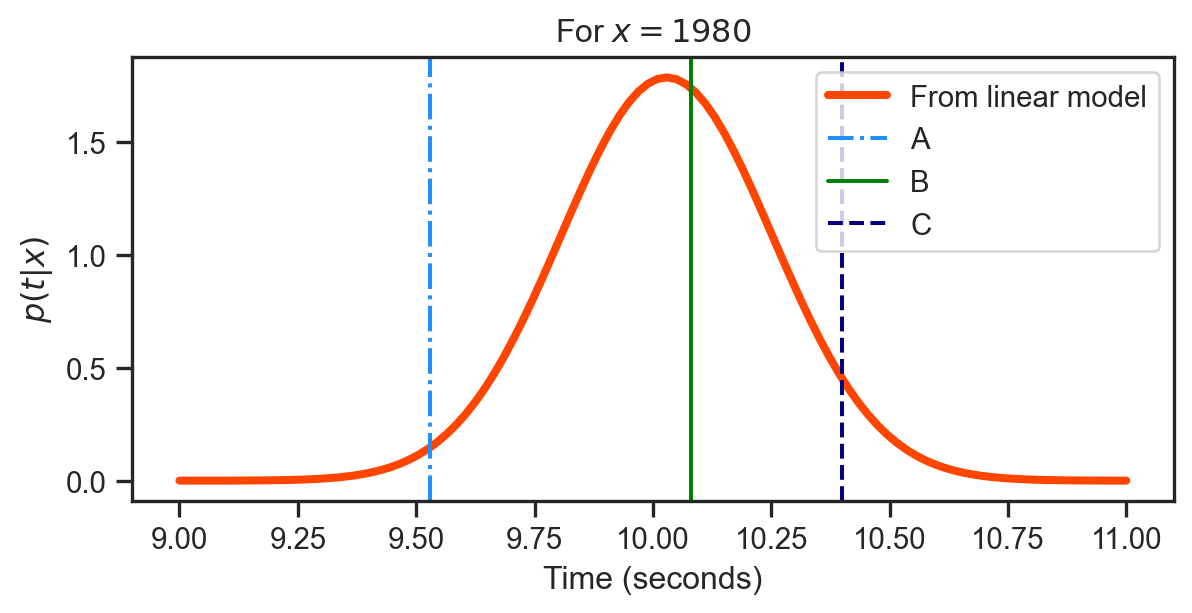
Note that for a continuous random variable t, p\left( t \right) cannot be interpreted as a probability.
The height of the curve to the left tells us how likely it is that we observe a particular t for x=1980.
The most likely is B, followed by C and then A. Note the actual winning time is t_{n}=10.25.
While we obviously cannot change the actual winning time, we can change \mathbf{{\color{blue}{w}}} and \sigma^2 to move the density to make it as high as possible at t=10.25.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from scipy.stats import multivariate_normal
# Get the data
df = pd.read_csv('notebooks/data/data100m.csv')
df.columns=['Year', 'Time']
N = df.shape[0]
max_year, min_year = df['Year'].values.max() , df['Year'].values.min()
x = (df['Year'].values.reshape(N,1) - min_year)/(max_year - min_year)
t = df['Time'].values.reshape(N,1)
X_func = lambda u : np.hstack([np.ones((u.shape[0],1)), u])
X = X_func(x)
w_hat = np.linalg.inv(X.T @ X) @ X.T @ t
# Specific year!
year_j = 1980
X_j = X_func(np.array( [ (year_j - min_year) / (max_year - min_year) ] ).reshape(1,1) )
time_j = float(X_j @ w_hat)
T_1980 = multivariate_normal(time_j, 0.05)
ti = np.linspace(9, 11, 100)
pt_x = T_1980.pdf(ti)
fig = plt.figure(figsize=(7,3))
plt.plot(ti, pt_x, '-', color='orangered', lw=3, label='From linear model')
plt.axvline(9.53, linestyle='-.', color='dodgerblue', label='A')
plt.axvline(10.08, linestyle='-', color='green', label='B')
plt.axvline(10.40, linestyle='--', color='navy', label='C')
plt.xlabel('Time (seconds)')
plt.ylabel(r'$p \left( t | x \right)$')
plt.title(r'For $x=1980$')
plt.legend()
plt.close()Maximum likelihood
Visualizing the Gaussian noise model
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font_scale=1.0)
sns.set_style("white")
sns.set_style("ticks")
palette = sns.color_palette('deep')
df = pd.read_csv('notebooks/data/data100m.csv')
df.columns=['Year', 'Time']
N = df.shape[0]
max_year, min_year = df['Year'].values.max() , df['Year'].values.min()
x = (df['Year'].values.reshape(N,1) - min_year)/(max_year - min_year)
t = df['Time'].values.reshape(N,1)
X_func = lambda u : np.hstack([np.ones((u.shape[0],1)), u ])
X = X_func(x)
w_hat = np.linalg.inv(X.T @ X) @ X.T @ t
loss_func = 1./N * (t - X @ w_hat).T @ (t - X @ w_hat)
xgrid = np.linspace(0, 1, 100).reshape(100,1)
Xg = X_func(xgrid)
time_grid = Xg @ w_hat
xi = xgrid*(max_year - min_year) + min_year
xi = xi.flatten()
sigma_hat_squared = float( (1. / N) * (t.T @ t - t.T @ X @ w_hat) )
sigma_hat = np.sqrt(sigma_hat_squared)
yi = xi* 0 + sigma_hat
loss_func = -N/2 * np.log(np.pi * 2) - N * np.log(sigma_hat) - \
1./(2 * sigma_hat_squared) * np.sum((X @ w_hat - t)**2)
fig = plt.figure(figsize=(6,4))
a, = plt.plot(df['Year'].values, df['Time'].values, 'o', color='crimson', label='Data')
plt.plot(xi, time_grid, '-', color='r')
c = plt.fill_between(xi, time_grid.flatten()-yi, time_grid.flatten()+yi, color='red', alpha=0.2, label='Model')
plt.xlabel('Year')
plt.ylabel('Time (seconds)')
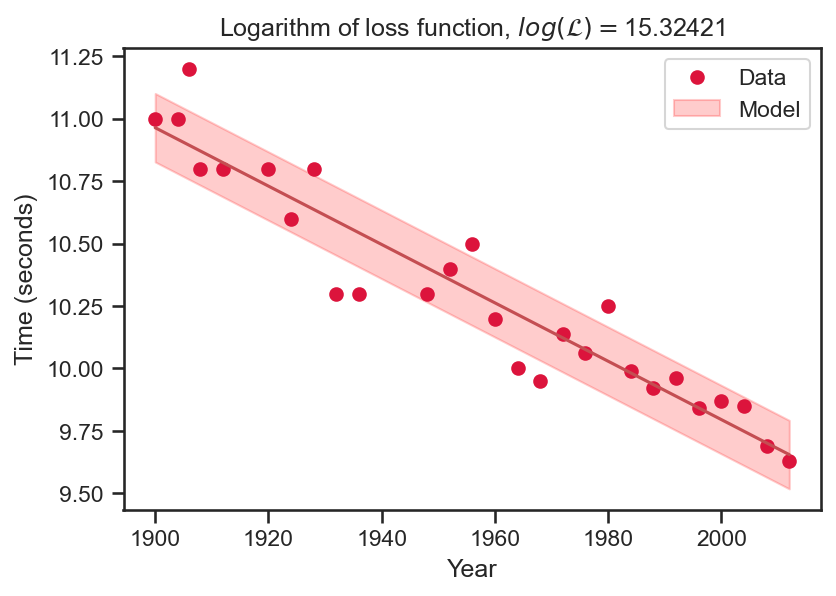
loss_title = r'Logarithm of loss function, $log \left( \mathcal{L} \right)=$'+str(np.around(float(loss_func), 5))
plt.title(loss_title)
plt.legend([a,c], ['Data', 'Model'])
plt.savefig('olympics_last.png', dpi=150, bbox_inches='tight')
plt.close()The graph on the left is the final model.