import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font_scale=1.0)
sns.set_style("white")
sns.set_style("ticks")
palette = sns.color_palette('deep')
plt.style.use('dark_background')
df = pd.read_csv('notebooks/data/data100m.csv')
df.columns=['Year', 'Time']
N = df.shape[0]
max_year, min_year = df['Year'].values.max() , df['Year'].values.min()
x = (df['Year'].values.reshape(N,1) - min_year)/(max_year - min_year)
t = df['Time'].values.reshape(N,1)
X_func = lambda u : np.hstack([np.ones((u.shape[0],1)), u ])
X = X_func(x)
xgrid = np.linspace(0, 1, 100).reshape(100,1)
Xg = X_func(xgrid)
xi = xgrid*(max_year - min_year) + min_year
xi = xi.flatten()
# We will assume we
sigma_hat = 0.4
M = 800
epsilon = np.random.randn(M, N) * sigma_hat
w_parameter = np.zeros((X.shape[1], M))
t_preds = np.zeros((100, M))
for j in range(0, M):
epsilon_j = epsilon[j,:].reshape(N,1)
t_j = t + epsilon_j
w_j = np.linalg.inv(X.T @ X) @ X.T @ t_j
w_parameter[:, j] = w_j.flatten()
t_preds[:,j] = (Xg @ w_j).flatten()
# Plot 1
fig, ax = plt.subplots(figsize=(6,4))
fig.patch.set_facecolor('#6C757D')
ax.set_facecolor('#6C757D')
a, = plt.plot(w_parameter[0,:], w_parameter[1,:], 'o', color='limegreen', \
label='Data', markeredgecolor='k', lw=1, ms=10, zorder=1, alpha=0.5)
plt.xlabel(r'$\mathbf{w}_0$')
plt.ylabel(r'$\mathbf{w}_1$')
plt.savefig('olympics_weights.png', dpi=150, bbox_inches='tight', facecolor="#6C757D")
plt.close()
# Plot 2
fig, ax = plt.subplots(figsize=(6,4))
fig.patch.set_facecolor('#6C757D')
ax.set_facecolor('#6C757D')
a, = plt.plot(df['Year'].values, df['Time'].values, 'o', color='dodgerblue', \
label='Data', markeredgecolor='k', lw=1, ms=10, zorder=1)
c = plt.plot(xi, t_preds, '-', color='gold', alpha=0.1, zorder=0)
plt.xlabel('Year')
plt.ylabel('Time (seconds)')
plt.legend([a,c[0]], ['Data', 'Model'], framealpha=0.1)
plt.savefig('olympics_linear.png', dpi=150, bbox_inches='tight', facecolor="#6C757D")
plt.close()Lecture 7
Towards Bayesian Inference
Gaussian noise model
Consider a scenario where rather than solving \hat{\mathbf{w}} = \left( \mathbf{X}^{T} \mathbf{X} \right)^{-1} \mathbf{X}^{T} \mathbf{t} we randomly perturb \mathbf{t} and work out \hat{\mathbf{w}} for each perturbed value, i.e., \hat{\mathbf{w}}_{j} = \left( \mathbf{X}^{T} \mathbf{X} \right)^{-1} \mathbf{X}^{T} \left( \mathbf{t} + \boldsymbol{\epsilon}_{j} \right), \; \; \; \; \text{where} \; \; \boldsymbol{\epsilon}_{j} \sim \mathcal{N} \left( \mathbf{0}, \sigma^2 \mathbf{I} \right).
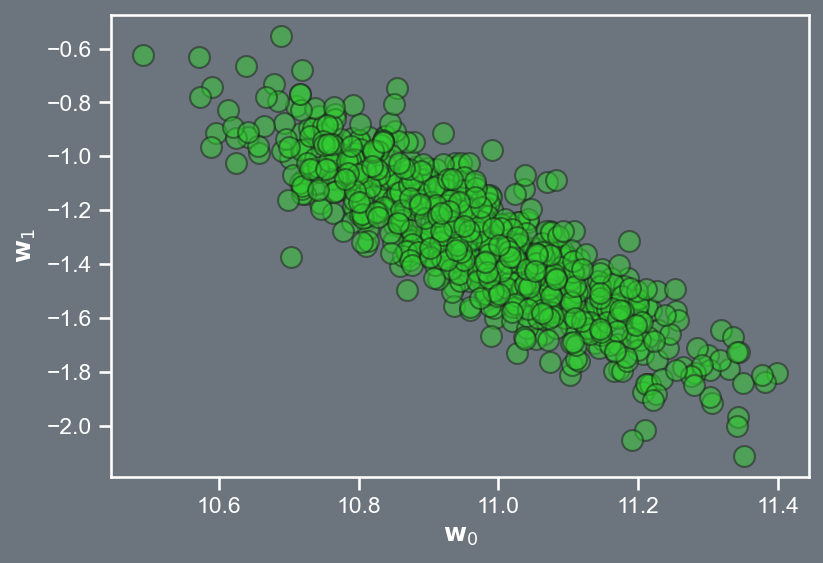
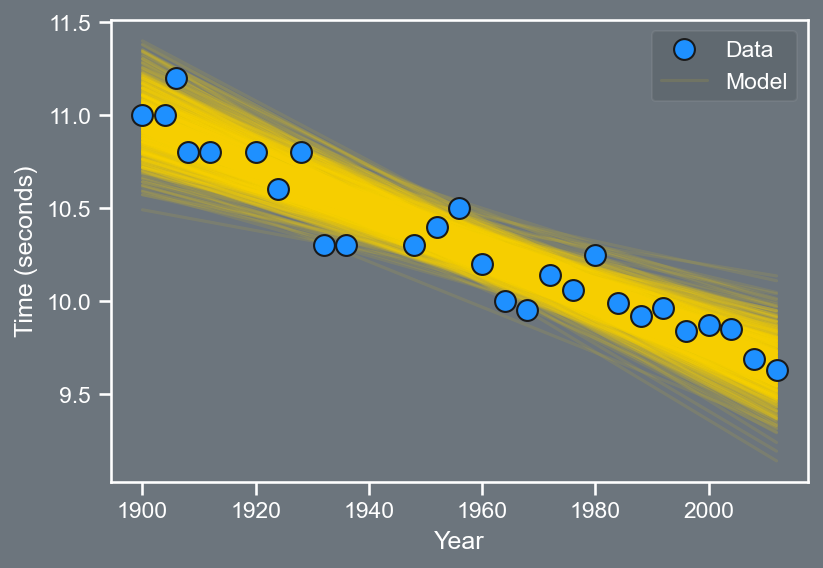
:::
Gaussian noise model
The matrix \sigma^2 \left( \mathbf{X}^{T} \mathbf{X} \right)^{-1} is the inverse of the Fisher Information matrix, \mathcal{I}, i.e., \mathcal{I} = \frac{1}{\sigma^2} \mathbf{X}^{T} \mathbf{X}.
The elements of this matrix tell us how much information the data provides: the more negative the information value is, the more information there is.
If the data is very noisy, the information content is lower.
 Image source: Royal Society
Image source: Royal Society
Gaussian noise model
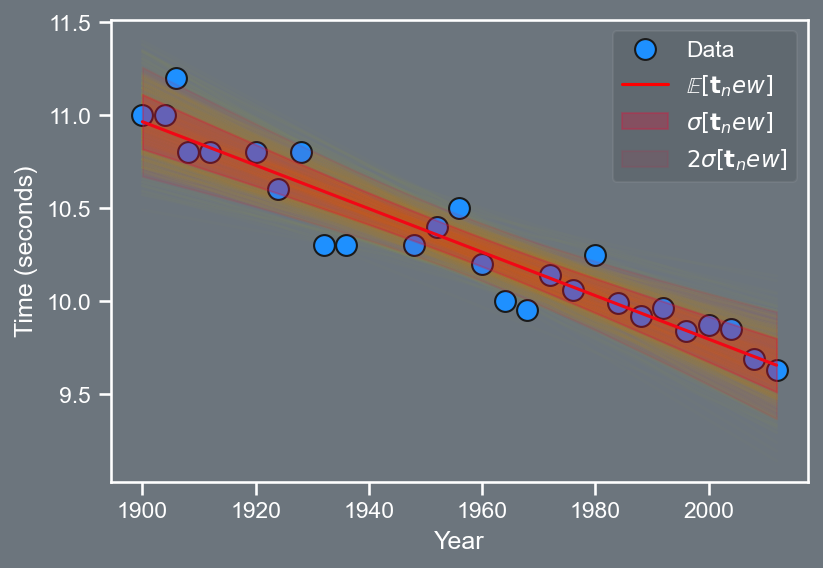
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font_scale=1.0)
sns.set_style("white")
sns.set_style("ticks")
palette = sns.color_palette('deep')
plt.style.use('dark_background')
df = pd.read_csv('notebooks/data/data100m.csv')
df.columns=['Year', 'Time']
N = df.shape[0]
max_year, min_year = df['Year'].values.max() , df['Year'].values.min()
x = (df['Year'].values.reshape(N,1) - min_year)/(max_year - min_year)
t = df['Time'].values.reshape(N,1)
X_func = lambda u : np.hstack([np.ones((u.shape[0],1)), u ])
X = X_func(x)
xgrid = np.linspace(0, 1, 100).reshape(100,1)
Xg = X_func(xgrid)
xi = xgrid*(max_year - min_year) + min_year
xi = xi.flatten()
# We will assume we
sigma_hat = 0.4
w_hat = np.linalg.inv(X.T @ X) @ X.T @ t
mean_t = (Xg @ w_hat).flatten()
cov_w = sigma_hat**2 * np.linalg.inv(X.T @ X)
cov_t = Xg @ cov_w @ Xg.T
std_t = np.sqrt(np.diag(cov_t)).flatten()
# Plot 1
fig, ax = plt.subplots(figsize=(6,4))
ax.set_facecolor('#6C757D')
fig.patch.set_facecolor('#6C757D')
a, = plt.plot(df['Year'].values, df['Time'].values, 'o', color='dodgerblue', \
label='Data', markeredgecolor='k', lw=1, ms=10, zorder=1)
c = plt.plot(xi, t_preds, '-', color='gold', alpha=0.01, zorder=0)
c, = plt.plot(xi, mean_t, '-', color='red', zorder=3)
d = plt.fill_between(xi, mean_t -std_t, mean_t + std_t, color='crimson', alpha=0.3, zorder=4)
e = plt.fill_between(xi, mean_t - 2 * std_t, mean_t + 2 * std_t, color='crimson', alpha=0.1, zorder=5)
plt.xlabel('Year')
plt.ylabel('Time (seconds)')
plt.legend([a,c,d, e], ['Data', r'$\mathbb{E}[\mathbf{t}_new]$', r'$\sigma[\mathbf{t}_new]$', r'$2 \sigma[\mathbf{t}_new]$'], framealpha=0.1)
plt.savefig('olympics_uncertainty.png', dpi=150, bbox_inches='tight', facecolor="#6C757D")
plt.close()Bayesian Model
Recall, earlier we had established that uncertainty in the model parameters \mathbf{\hat{w}} can be used to explain uncertainty in the data \mathbf{t}.
We now introduce the notion of a prior to \mathbf{w}. To clarify, when introducing a prior to \mathbf{w}. For no better reason for now, we will assume a Gaussian distribution, i.e., p \left( \mathbf{w} | \boldsymbol{\mu}_{0}, \boldsymbol{\Sigma}_{0} \right) = \mathcal{N} \left( \boldsymbol{\mu}_{0}, \boldsymbol{\Sigma}_{0} \right) where the choice of the mean \boldsymbol{\mu}_{0} and covariance \boldsymbol{\Sigma}_{0} is typically selected by the user / practitioner.
From a notation standpoint, note that we will not explicitly condition on \boldsymbol{\mu}_{0} and \boldsymbol{\Sigma}_{0}, i.e., we will use p \left( \mathbf{w} | \mathbf{t}, \mathbf{X}, \sigma^2 \right) instead of p \left( \mathbf{w} | \mathbf{t}, \mathbf{X}, \sigma^2, \boldsymbol{\mu}_{0}, \boldsymbol{\Sigma}_{0} \right).
Scatter in the model parameters, \mathbf{w}.
Bayesian Model
Prior
p \left( \mathbf{w} \right)
Likelihood
p \left( \mathbf{t} | \mathbf{w}, \mathbf{X}, \sigma^2 \right)
Posterior
p \left( \mathbf{w} | \mathbf{t}, \mathbf{X}, \sigma^2 \right)where
- \mathbf{X} encodes the model attributes (or inputs or covariates),
- \mathbf{t} are the observed values (or outputs), and
- \sigma^2 in this case is an assumed noise.
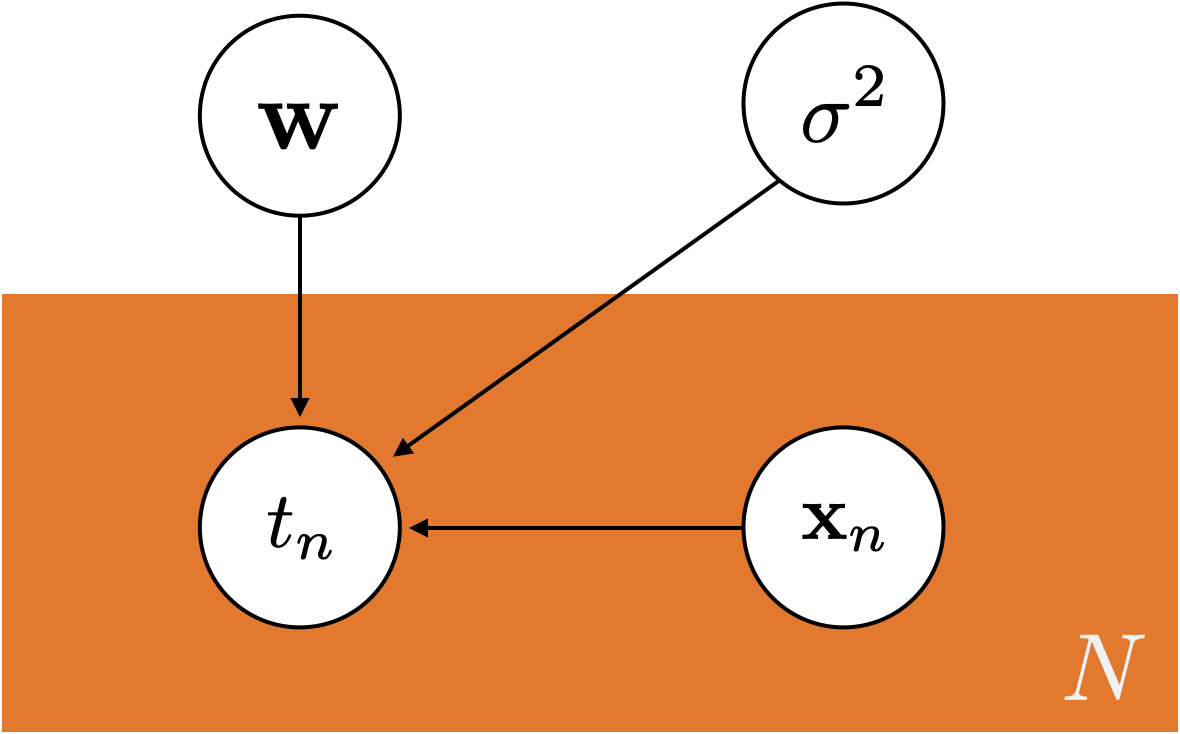
A graphical representation of the model.