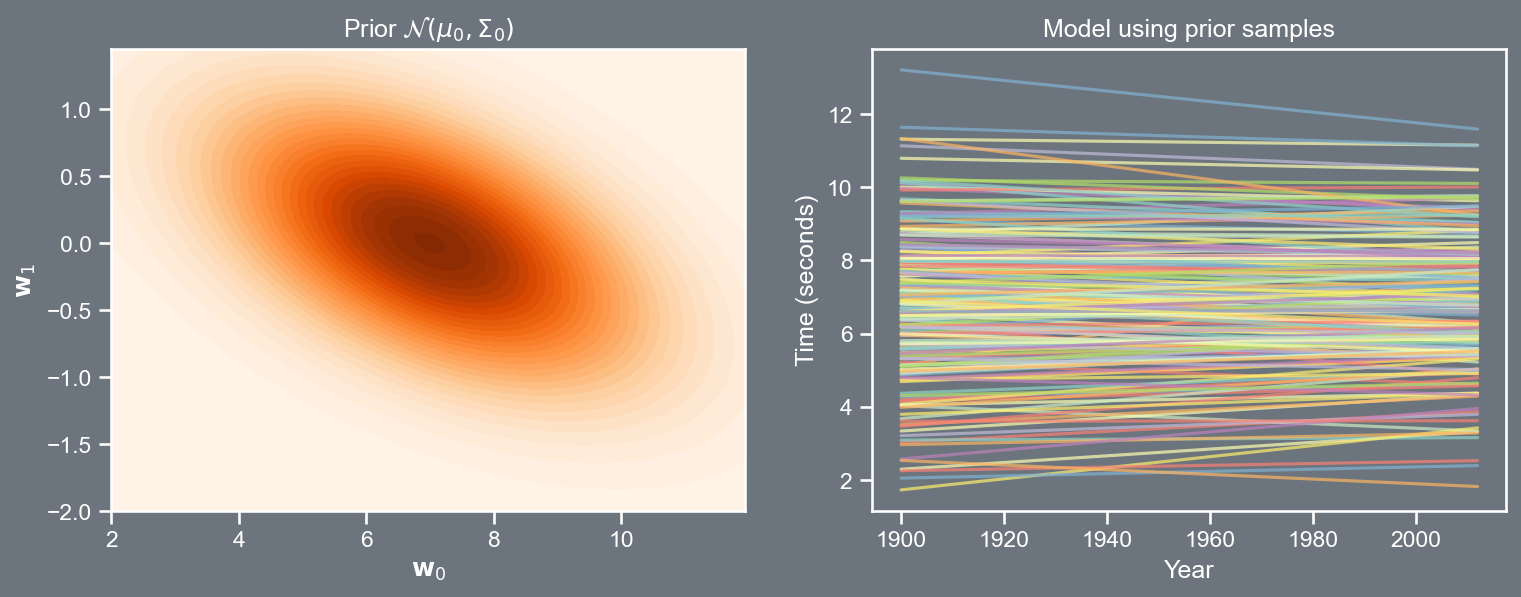
The quadratic terms in \mathbf{w} in Equation 3 must match those we had in Equation 1. Thus we can write
\begin{aligned}
\mathbf{w}^{T} \boldsymbol{\Sigma}_{\mathbf{w}}^{-1} \mathbf{w} & = \frac{1}{\sigma^2} \mathbf{w}^{T} \mathbf{X}^{T} \mathbf{X} \mathbf{w} + \mathbf{w}^{T} \boldsymbol{\Sigma}_{0}^{-1} \mathbf{w} \\
& = \mathbf{w}^{T} \left( \frac{1}{\sigma^2} \mathbf{X}^{T} \mathbf{X} + \boldsymbol{\Sigma}_{0}^{-1} \right) \mathbf{w}
\end{aligned}
As for the expectation, we equate the linear terms in Equation 1 with those in Equation 3
\begin{aligned}
-2 \boldsymbol{\mu}_{\mathbf{w}}^{T} \boldsymbol{\Sigma}_{\mathbf{w}}^{-1}\mathbf{w} = - \frac{2}{\sigma^2} \mathbf{t}^{T} \mathbf{Xw} - 2 \boldsymbol{\mu}_{0}^{T} \boldsymbol{\Sigma}_{0}^{-1} \mathbf{w}
\end{aligned}
If we set the prior mean to be zero, i.e., \boldsymbol{\mu}_{0} = \left[ 0, 0, \ldots, 0 \right]^{T}, the resulting value of \boldsymbol{\mu}_{\mathbf{w}} looks very similar to the maximum likelihood solution from before.
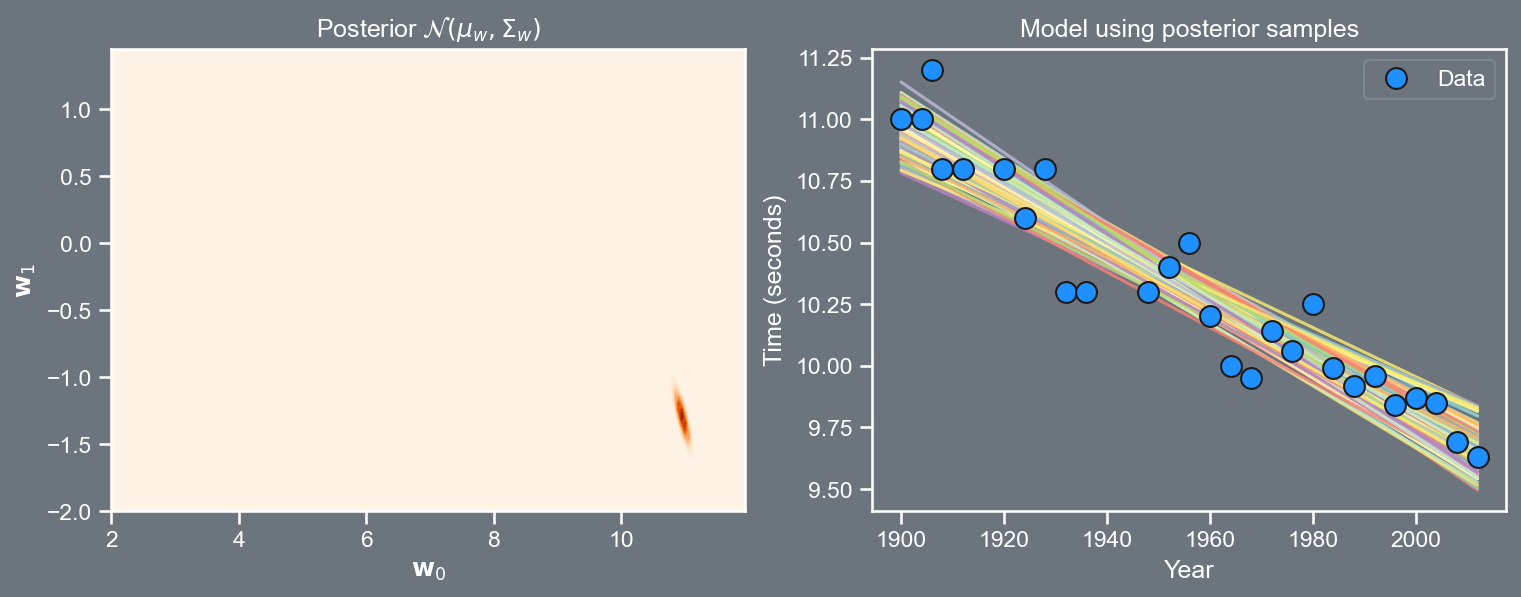
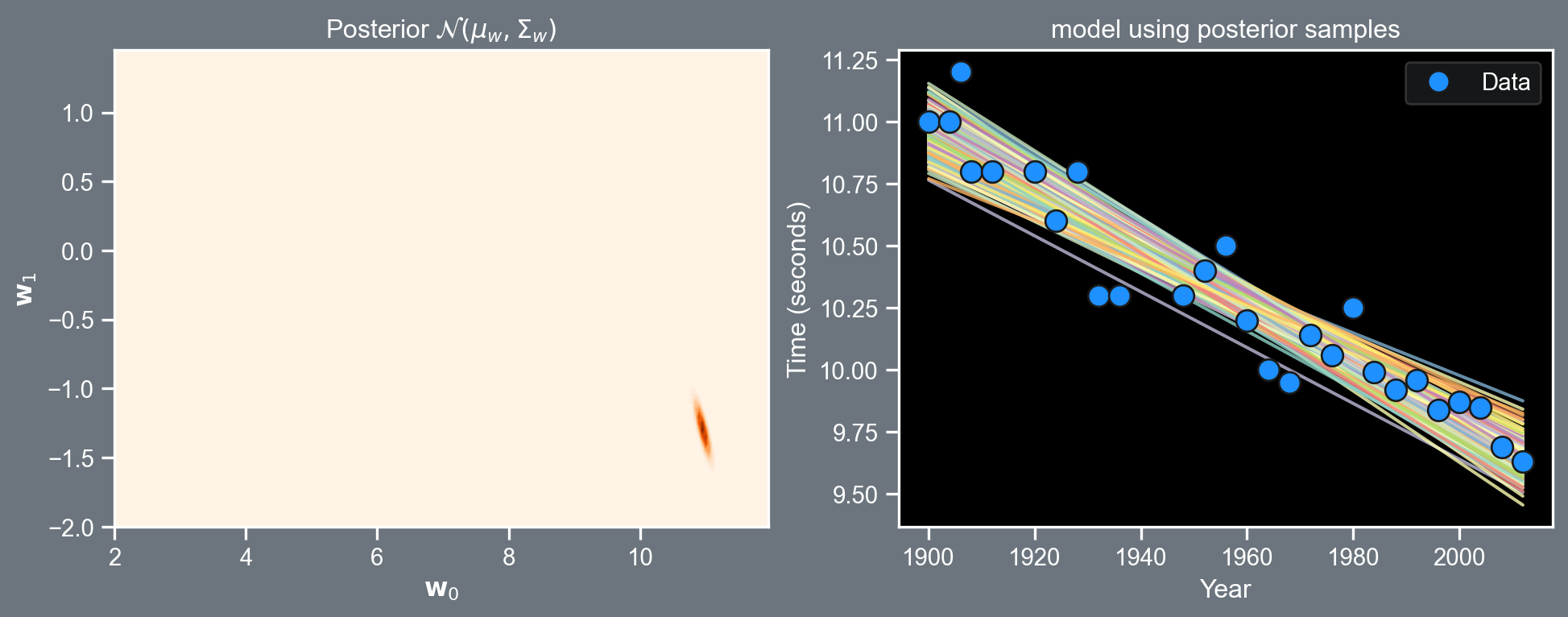
Note, that because the posterior p \left( \mathbf{w} | \mathbf{t}, \mathbf{X}, \sigma^2 \right) is Gaussian, the most likely value of \mathbf{w} is the mean of the posterior, \boldsymbol{\mu}_{\mathbf{w}}. .
This is known as the maximum a posteriori (MAP) estimate of \mathbf{w} and can also be thought of as the maximum value of the joint density p \left( \mathbf{w}, \mathbf{t} | \mathbf{X} \sigma^2, \boldsymbol{\mu}_{0}, \boldsymbol{\Sigma}_{0} \right) (which is the likelihood \times prior).
Bayesian model
Predictive density
Just as we did last time, it will be useful to make predictions. To do this, we once again use \mathbf{X}_{new} \in \mathbb{R}^{S \times 2} where S is the number of newx locations (in this case time) at which our model needs to be evaluated, i.e.,
\mathbf{X}_{new}=\left[\begin{array}{cc}
1 & x^{new}_{1}\\
1 & x^{new}_{2}\\
\vdots & \vdots\\
1 & x^{new}_{S}
\end{array}\right]
We are interested in the predictive density
p \left( \mathbf{t}_{new} | \mathbf{X}_{new}, \mathbf{X}, \mathbf{t}, \sigma^2 \right)
Notice, that this density is not conditioned on \mathbf{w}. We are going to integrate out \mathbf{w} by taking an expectation with respect to the posterior p \left( \mathbf{w} | \mathbf{t}, \mathbf{X}, \sigma^2 \right), i.e.,
This leads to the predictive density form given by
p \left( \mathbf{t}_{new} | \mathbf{X}_{new}, \mathbf{X}, \mathbf{t}, \sigma^2 \right) = \mathcal{N} \left( \mathbf{X}_{new} \boldsymbol{\mu}_{\mathbf{w}} , \sigma^2 \mathbf{I} + \mathbf{X}_{new}^{T} \boldsymbol{\Sigma}_{\mathbf{w}} \mathbf{X}_{new} \right)
\tag{4}
Try proving this yourself! You may find section 2.3.2 of Bishop useful
The inclusion of the \sigma^2 \mathbf{I} term is optional, i.e., if we wish to replicate the true signal (without noise) this can be negated. However, if we wish to model the realistic data generation process then the noise should be incorporated.
A likelihood-prior pair is said to be conjugate if they result in a posterior which is of the same form as the prior.
This enables us to compute the posterior density analytically (as we have done) without having to worry about the marginal likelihood (the denominator in Bayes’ rule).
Some commonly used prior and likelihood distributions are given below.
Prior
Likelihood
Gaussian
Gaussian
Beta
Binomial
Gamma
Gaussian
Dirichlet
Multinomial
Bayesian model
Marginal likelihood re-visited
The marginal likelihood for a Bayesian model is given by
\text{marginal likelihood} = \int \text{likelihood} \times \text{prior} \; d \mathbf{w}
The marginal likelihood for our Gaussian prior and Gaussian likelihood model is given by
\begin{aligned}
p \left( \mathbf{t} | \mathbf{X}, \boldsymbol{\mu}_{0}, \boldsymbol{\Sigma}_{0} \right) & = \int p \left( \mathbf{t} | \mathbf{X}, \mathbf{w}, \sigma^2 \right) p \left( \mathbf{w} | \boldsymbol{\mu}_{0} , \boldsymbol{\Sigma}_{0} \right) d \mathbf{w} \\
& = \mathcal{N} \left( \mathbf{X} \boldsymbol{\mu}_{0}, \sigma^2 \mathbf{I}_{N} + \mathbf{X} \boldsymbol{\Sigma}_{0} \mathbf{X}^{T} \right)
\end{aligned}
Note that it has the same form as Equation 4, and it is evaluated at \mathbf{t}, i.e., the observed winning times.
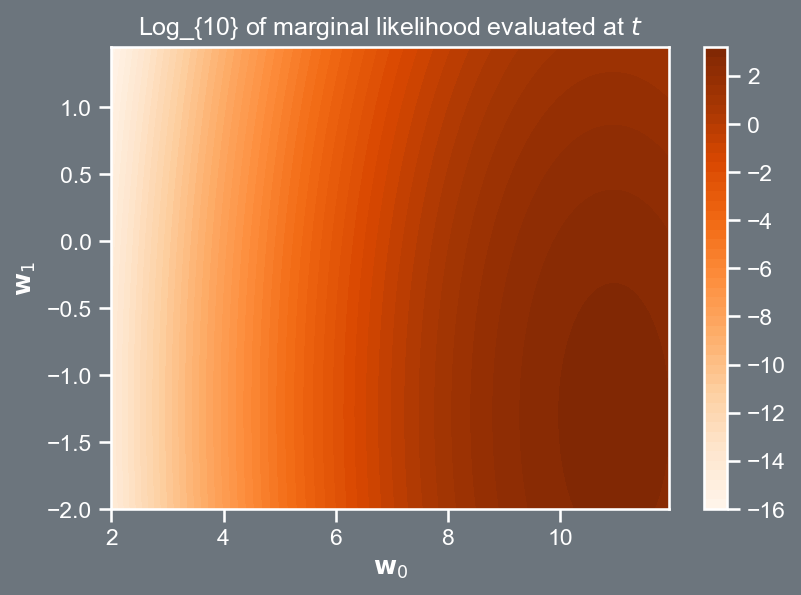
The plot on the right shows the logarithm of the marginal likelihood.
Note that where the contours peak corresponds to values of \mathbf{w} that better explain the data \mathbf{t}, given its uncertainty \sigma^2, and the model as encoded into \mathbf{X}.
Sampling \mathbf{t} conditioned on \mathbf{w} vs. sampling \mathbf{t} directly from the marginal likelihood are statistically equivalent.
Removing \mathbf{w} from our model (effectively making it non-parametric) opens the door to thinking of priors in the space of functions, and not just in the space of model parameters.
This is arguably one of the main ideas in Gaussian processes, that I will introduce next time we meet.